
The Tool Call Is the Attack Surface
How autonomous agents break the front-door/back-door model.


Software used to wait. A program sat still until you told it what to do, did exactly that, and stopped. Even the first wave of generative assistants kept the arrangement intact. They suggested; you decided. You typed a prompt, read a response, and chose whether to act on it. The machine proposed and the human disposed. That division of labor held for thirty years, so reliable we stopped noticing it was there.
Autonomous agents end it. An agent senses its environment, reasons about what it finds, and acts without checking back. It calls tools. It runs code. It hands work to other agents and reads their answers as fact. The loop that used to pass through a person closes on itself. This isn’t a faster assistant. It’s a different kind of actor, and the difference is the whole story.
The Window Opens

We’ve been slow to update our defenses because the old ones felt sufficient. When the only thing a model could do was return text, you guarded two doors. You checked the input for anything malicious or manipulative, and you checked the output for anything false or harmful. Guard the prompt, inspect the answer, and you’d covered the model’s entire contact with the world. A generation of safety tooling grew up around those two points.
Here’s what changes when the model can act. The input and the output are no longer where the danger lives. An agent’s real exposure sits in the middle, in the moment it decides to call a tool and the moment that tool returns a result. That’s where it reaches into a database, sends a message, moves money, executes a script. A system that only screens the prompt and the final answer is guarding the front door and the back door of a house while leaving every window open. The intruder doesn’t knock. He climbs through the tool call.
And the call has two halves, each one open in its own way. Going out, the agent reaches into the world and acts. Coming back, the tool hands it a result it treats as true, and that return is the softer target. An attacker who can’t reach your prompt can still poison what a tool gives back: a retrieved web page with instructions buried in its text, a document that tells the agent to disregard what it was told a moment ago. The agent can’t tell the command from the data. It asked a question, got an answer, and the answer was the attack. You screened the user’s prompt and it didn’t matter; the injection came through the tool.
The Disciplines We Already Have
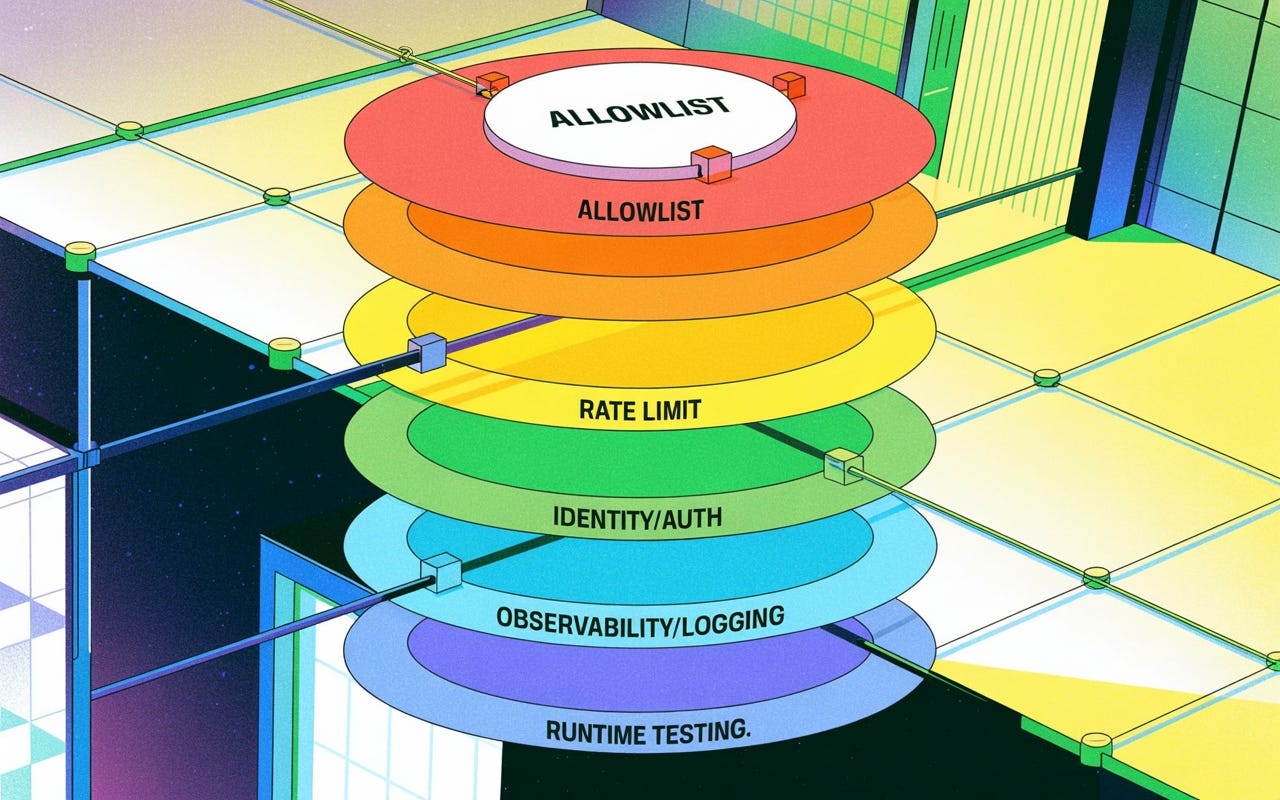
Once you see that the control surface has moved, the work gets clearer, and oddly, less novel. The instinct in a new field is to invent new safeguards. The better instinct is to ask which old ones we left at the door. Most of what an autonomous agent needs, we already practice on every serious distributed system. We just have to apply it to a stranger kind of participant.
Scope
Start with what an agent is allowed to do. A capable agent can reason about almost anything, and that’s fine; reasoning is cheap and contained. Acting is neither. So you separate the two. Let the agent think freely, but let it act only through a list of operations you’ve approved in advance. Anything off the list doesn’t run. This sounds obvious until you notice how many deployments skip it, handing an agent a broad set of tools and trusting it to choose well because it usually does. Usually is not a security posture.
Budget
And the boundary isn’t only about which operations an agent may perform. It’s about how many times. Each action an agent takes costs something: a query, a compute cycle, a call to a paid service. An agent with no ceiling on its activity is a denial-of-service weapon aimed at your own infrastructure, and it doesn’t need an attacker to become one. A confused agent stuck in a loop will do the damage by itself. So you give it a budget. This many actions per session, logged with a session identifier, every call recorded. Now you have a brake and a paper trail in the same mechanism.
Identity
Then there’s the question of who the agent is. We spent years learning not to let services talk to each other on trust alone. Every service authenticates; every request carries proof of where it came from; nothing inside the perimeter gets a free pass. Autonomous agents need the same treatment, and they need identities of their own to get it. An agent isn’t its user, and it isn’t an ordinary service account. It’s something new, and it should carry credentials of its own, so that when one agent calls another, both can verify the other is exactly what it claims to be and reject it when the claim doesn’t hold. The zero-trust posture we built between services is the right posture between agents. We just have to issue the agents passports.
Observability
None of this works if you can’t see what happened. Observability is the floor the whole structure rests on, because a control you can’t observe is a control you can’t enforce. You want a record of which model ran, how much it consumed, which agent made each call, and what came back. You want alerts when an agent’s activity spikes or its authentication starts failing in patterns that don’t fit normal use. And you want one when a tool returns something shaped more like a command than an answer, because that’s the injection from earlier showing up where you can still catch it. This, too, isn’t new. It’s the monitoring discipline every mature operation already runs, extended to a new kind of process. The agent is just another thing in production that you refuse to fly blind on.
Runtime Testing
What is new is the rhythm of checking. We’re used to certifying software once, before it ships, and trusting the certificate until the next release. Agents break that habit. Their behavior drifts. An agent that acts fairly and stays on task in its first exchange can accumulate bias or wander off its purpose ten turns into a long conversation, shaped by everything that came before. A single pre-launch test can’t catch a failure that only emerges in use. So the testing moves inside the running system. You run adversarial probes on a schedule against live agents, measure how often an attack succeeds, and watch that number after every change. If it climbs, something regressed, and you learn it in days rather than after an incident.
What We Can’t Yet See
It’s worth being honest about where this breaks down. We can name the failure modes faster than we can measure them: the slow drift, the agent that treats one person differently from another based on what it absorbed mid-conversation. The tooling to catch unfairness in a running agent is thin, and pretending otherwise helps no one. Some of these problems we can only watch for now, not yet prevent. That’s not a reason to wait. It’s a reason to build the parts we can and stay loud about the parts we can’t.
Regulation
The rules are arriving regardless. Lawmakers are beginning to require human oversight for high-stakes automated decisions and clear disclosure when a person is dealing with a machine rather than another person. These obligations land more lightly on teams that already log their agents’ actions, already disclose when an answer came from a model, already keep a human reachable for the decisions that matter. The accountability the regulators want is the accountability good engineering was already producing.
The Surface

So the temptation, faced with autonomous agents, is to treat them as a frontier that demands a brand-new rulebook. They don’t. They demand that we move an old rulebook to a new place. We used to guard the doors, the prompt going in and the answer coming out. The agent doesn’t use the doors. It works through the window, in the gap between deciding to act and seeing what the act returns. That gap is the surface now. That’s where you stand.